Prozess-Autopiloten für die Lebensmittelindustrie
Die Verarbeitung großer Datenmengen mittels neuronaler Netze kann dabei helfen, biotechnologische Prozesse, wie jene in der Lebensmittelindustrie, besser zu verstehen, zu automatisieren und stabiler zu machen.

Um die dafür benötigten Messwerte zu generieren, sind in der Praxis allerdings innovative analytische Verfahren nötig, die in der Industrie noch keinen Einzug gefunden haben.
Aus vielen Bereichen des täglichen Lebens ist der Einsatz von neuronalen Netzen nicht mehr wegzudenken: Die Handykamera erkennt autonom, wo auf einem Foto die Gesichtspartie zu sehen ist, auf Grundlage unserer bereits gesehenen Filme spuckt der Smart-TV neue Vorschläge aus, die uns gefallen könnten [1] und Logistikunternehmen verlassen sich auf die Vorhersage des Verkehrsaufkommens, um zu Stoßzeiten die beste Route zu ermitteln. Man kann also festhalten: Datengetriebene Modelle sind in zahlreichen Einsatzgebieten angekommen und werden so schnell nicht wieder verschwinden. Doch einige Fachgebiete leisten erbitterten Widerstand – zumindest erweckt es diesen Anschein, wenn man z. B. die biotechnologische Herstellung von Lebensmitteln betrachtet. Als Stellvertreter dieser sollen in diesem Artikel zwei Prozesse dienen, die etwas mit dem Organismus Hefe zu tun haben: Die Hefeherstellung im industriellen Maßstab, sowie die Produktion von Bier und weiteren Getränken in Brauereien.
Außer der Verwendung desselben Produktionsorganismus gibt es nämlich weitere Gemeinsamkeiten dieser Industrien: Niedrige Gewinnspannen, schwankende Rohstoffqualitäten und eine eher konservative Prozessführung.
Da es sich bei beiden Beispielen nicht gerade um neue Prozesse handelt – das erste Bier der Welt brauten vermutlich bereits die Sumerer vor fünf Jahrtausenden – könnte man annehmen, dass die Prozessführung inzwischen bis ins kleinste Detail optimiert wurde und somit jeder Prozess das gewünschte, ideale Ergebnis liefert. Dies wird in der Realität jedoch durch einige Faktoren verhindert. So ist bspw. die Zusammensetzung des in der Brauerei verwendeten Malzes saisonalen Schwankungen unterworfen [2]. Gleiches gilt für die Melasse, welche in der Hefe-herstellenden Industrie als Substrat zum Einsatz kommt. In der Brauerei können sich so während der Gärung unerwünschte Nebenprodukte einschleichen, die den Geschmack negativ beeinflussen können, während in der Hefeherstellung die Dosierung des Substrats absichtlich niedriger angesetzt wird als möglich, um eine Überfütterung und damit einhergehende Verringerung der Hefe-Ausbeute pro Gramm Substrat zu verhindern.
Dass regelmäßige Schwankungen der Rohstoffe auftreten, ist keine Überraschung, und der Einfluss auf den späteren Prozess zumindest teilweise bekannt. Warum kann es also trotzdem zu Schwankungen im Prozessergebnis kommen? Zum einen liegt das an mehr oder minder starren Prozesskontrollstrategien, die auf der Expertise und Erfahrung z. B. des Braumeisters beruhen und somit bewusst auf der „sicheren Seite“ bleiben. Zum anderen ist es aber auch eine Preisfrage: Die Analytik der Substrate hinsichtlich ihrer exakten Zusammensetzung ist relativ teuer im Vergleich zum finanziellen Verlust durch etwaige suboptimal gefahrene Prozesse. Generell handelt es sich prozesstechnisch um wenig komplexe Prozesse, weshalb während der Produktion kaum Messwerte aufgenommen werden.
Wenn man versuchen möchte, KI-Systeme in diesen Industrien einzusetzen, ergibt sich demnach folgendes Anforderungsprofil: Einfach einzusetzende, kostengünstige Messtechnik zur Datenerhebung bei gleichzeitiger Optimierung der Prozessführung. Ein möglicher Pfad zur Umsetzung dieser Ziele soll im Folgenden beschrieben werden.
Datengenerierung in parallelen Ansätzen
Um die Herausforderung der Gewinnung nötiger Prozessdaten zu lösen, müssen kostengünstige Alternativen zur herkömmlichen Analytik gefunden werden. Diese sollten zum Durchführen mehrerer Versuche gleichzeitig geeignet sein, um die Datensammlungs- bzw. Entwicklungsphasen kurz zu halten und wertvolle Rückschlüsse über den Prozess in Echtzeit zulassen. Für biotechnologische Prozesse eignen sich hier bspw. Abgasmessungen. Diese sind nichtinvasiv, reagieren schnell auf Änderungen und liefern Hinweise auf die metabolische Aktivität der Produktionsorganismen. Im deepLAB-System, entwickelt an der Westfälischen Hochschule, kommen eigens entworfene Abgassensoren zum Einsatz (Abb. 1). Dabei handelt es sich um in Gehäuse aus dem 3D-Drucker eingebettete Platinen mit elektrochemischen Sensoren, die über diverse (ebenfalls 3D-gedruckte) Adapterstücke auf typischerweise im Labor genutzte, genormte Gewinde wie z. B. einen GL 45 Schraubverschluss passen. Diese Herangehensweise sorgt dafür, dass die Kosten niedrig bleiben und trotzdem ein flexibles und skalierbares Messsystem entsteht.
Der zu messende Analyt ist in diesem Fall Ethanol, ein wichtiger Indikator für den sogenannten Overflow-Metabolismus der Hefe, also einem Zustand in dem mehr Substrat vorhanden ist als die Hefezellen über aerobe Atmungsprozesse verbrauchen können. [3] Wenn die Detektoren also einen Messwert anzeigen, ist der Fall eingetreten, den die Hefehersteller gerne vermeiden möchten – die eingesetzte Melasse wurde zu schnell hinzugefüttert, sodass neben dem gewünschten Produkt (Hefezellen) auch Nebenprodukt (Ethanol) entstanden ist, was die Ausbeute und somit letztlich die Gewinnspanne der Produzenten reduziert.
Die genauen Umgebungsbedingungen, bei denen dieser Fall eintritt, lassen sich mit einem System wie dem deepLAB in miniaturisierten, sogenannten „Scale-down“-Experimenten schnell nachstellen. Durch die Kompatibilität zu verschiedenen Gewinden können hierfür einfache Glasflaschen als Kulturgefäße dienen, sodass kein teures Equipment angeschafft werden muss.
Training von Prozessmodellen
Die auf diese Art und Weise generierten Datensätze können nun für das Erstellen mathematischer Modelle benutzt werden, welche in der Lage sind, die Bioprozesse zu beschreiben oder sogar zu steuern. Den Workflow der datengetriebenen Modellierung wurde von den Autoren bereits in der GIT Labor-Fachzeitschrift 04/2020 ausführlich beschrieben. [4] Die beschriebenen Arbeitsschritte (Datenmanagement, Preprocessing, Modelltraining, -Validierung und -Monitoring) können z. B. mit der Virtual Sensors-Software (Abb. 2) durchgeführt werden
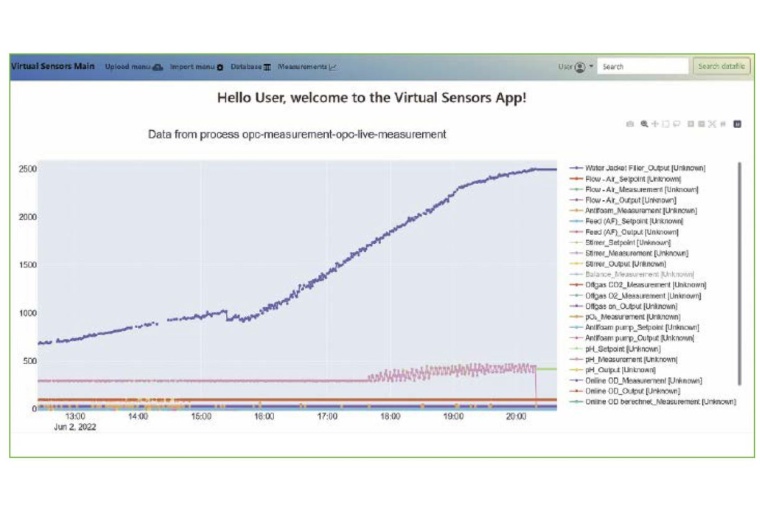
Nach der Datengewinnung, -auswertung und -vorverarbeitung kann das Training eines geeigneten Modells beginnen. Im Anwendungsfall der Hefehersteller ist das System bspw. auf die Ethanolkonzentration als Zielgröße trainiert, während die Substratzufuhr eine Input-Größe darstellt. Mit so einem Modell kann anschließend in silico die Fütterungsrate variiert werden, um die maximale Zuflussrate des Substrates zu ermitteln, bei der noch kein Overflowmetabolismus beobachtet werden kann.
Ein solches Modell nennt man auch ein Expertensystem für den Prozess. Dieses wird anfangs zunächst eine Hilfestellung für den (menschlichen) Prozessleiter darstellen, um zu überprüfen, ob das vorhergesagte Verhalten der Hefeorganismen auch valide ist. Ist das Vertrauen in den Algorithmus groß genug, kann sich eine automatisierte Regelung des Prozesses auf Basis der Modellergebnisse anschließen.
Um eine solche Automatik zu gewährleisten, bedarf es geeigneter Schnittstellen, um Prozessdaten in Echtzeit an das trainierte Modell und dessen Ergebnisse zurück auf das Prozessleitsystem zu spielen. Dafür hat sich z. B. die OPC Unified Architecture (OPC UA) als Standard in vielen Bereichen etabliert. Mit diesem 2006 erstmalig veröffentlichten Protokoll können Geräte verschiedener Hersteller als Client und Server miteinander vernetzt werden, um Informationen auszutauschen [5]. Entsprechend können Prozessleitsysteme mit OPC UA Server-Funktion die Sensordaten verschiedener Geräte bündeln und per Netzwerk verfügbar machen. Ein zweites Gerät, bspw. ein Computer an einem anderen Standort, kann die Sensordaten dann (bei Bedarf verschlüsselt) empfangen, sie als Input für ein vortrainiertes Modell verwenden und das Ergebnis dieser Operation an den Server zurückspielen.
Genau zu diesem Zweck kann das deepLAB-Portfolio durch die OPC-Box erweitert werden. Dabei handelt es sich um ein Gerät, das mit besagter OPC UA-Schnittstelle und einem fertig trainierten Prozessmodell ausgestattet ist, um bei Anwendern ohne großen Eingriff in die EDV mit einem Prozessleitsystem zu kommunizieren und eine direkte Anwendung datengetriebener Modelle in verschiedenen Szenarien ermöglicht.
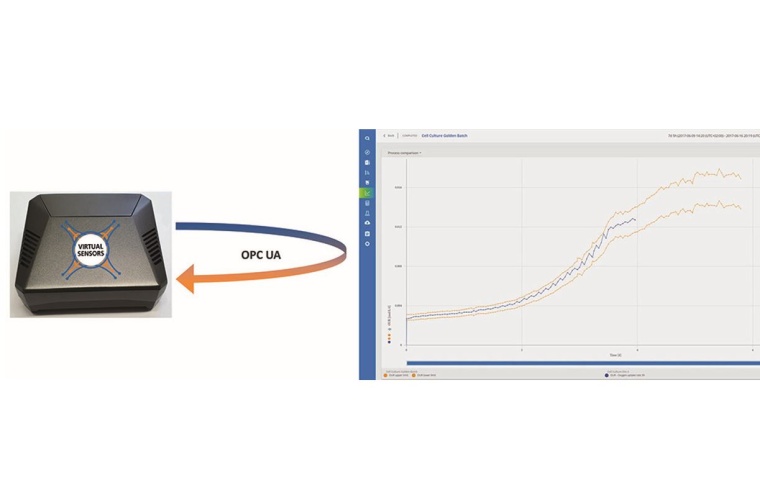
Automatisierte Prozesskontrolle auf Modellbasis
Wenn ein Modell erstellt wurde, das die gewünschte Präzision und Robustheit aufweist, kann es schließlich für die automatisierte Prozesskontrolle eingesetzt werden. Dabei können die Anwendungsmöglichkeiten sehr vielfältig sein, da sie von der Architektur des Modells, den verfügbaren Mess- und Steuerungsgrößen und natürlich der Fragestellung abhängig sind. In diesem Artikel soll als Beispiel eine Art „Autopilot“ für Bioprozesse vorgestellt werden. Das ist ein datengetriebenes Modell, welches den Prozess durch Ansteuern verschiedener Aktoren wieder in den erwarteten Prozesskorridor bringen soll, falls er droht davon abzuweichen.
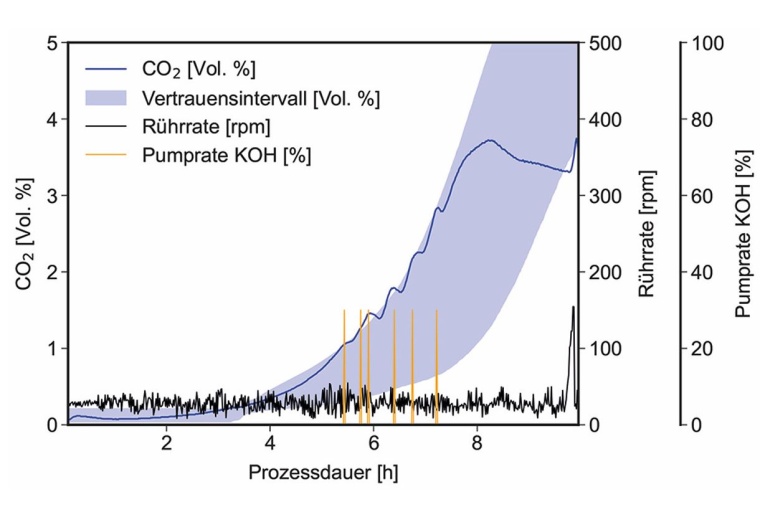
Dazu sind mehrere Komponenten nötig: Zunächst wird der gewünschte Prozesskorridor festgelegt. Im gezeigten Beispiel wurden dafür statistische Mittel auf den Trainings-Datensatz des Prozessmodells angewendet, um den Mittelwert der Zielgröße als Vertrauensbereich mit einem Konfidenzniveau von 95 % zu berechnen. Der so ermittelte Verlauf dient dem System als Vorlage für einen „normalen“ Prozess.
Die zweite Komponente ist ein prädiktives Prozessmodell, welches als Input-Größen (u. a.) diejenigen Stellgrößen verwendet, welche Einfluss auf die Zielgröße haben können. Im Beispiel der Hefeherstellung könnte das ein Modell ergeben, das auf Basis der Zufütterungsrate und weiterer Inputgrößen die Wahrscheinlichkeit der Ethanolproduktion vorhersagt. In Kombination mit dem oben erwähnten Konfidenzniveau ergibt sich so ein Frühwarnsystem, das ein Verlassen des gewünschten Prozesskorridors vorhersehen und gegebenenfalls verhindern kann. Ein solcher Algorithmus wäre in der Lage, rechnerisch die Substratgabe zu maximieren, während gleichzeitig ein Überfütterungseffekt vermieden wird. Somit ermöglicht es eine Anpassung der Prozessführung, bevor die kritische Menge an Substrat überschritten wurde und verhindert so eine Verringerung der Ausbeute.
In Abbildung 4 ist ein exemplarischer Verlauf eines Prozesses dargestellt, der über eine solche Regelungsautomatik gesteuert wurde. Dabei wurde über die 15 Versuche im Trainings-Set ein Vertrauensbereich für den CO2-Verlauf im Abgas erstellt. Als Aktoren kamen der Rotor des Rührwerks und eine Pumpe mit einer Kaliumhydroxid-Lösung zum Einsatz. Stieg der Messwert des CO2-Sensors über die obere Grenze des Vertrauensbereichs an, wurde über die Pumpe die basische Korrekturlösung in den Reaktor gepumpt, was den CO2-Ausstoß der Kultur nach unten korrigierte. Wurde die untere Grenze verlassen, registrierte das System dies und erhöhte die Rührrate, um die Sauerstoffversorgung zu verbessern. Insgesamt konnte durch diesen Autopiloten der Versuch über weite Strecken vollautomatisch im gewünschten Prozesskorridor gehalten werden.
Fazit
Datengetriebene Modelle können für die automatisierte Prozessführung enorm mächtige Tools sein. Sie ermöglichen es, von der Norm abweichende Produktionsläufe autonom zu erkennen, liefern Hinweise für deren Ursache und können als Expertensysteme den menschlichen Operatoren zur Seite stehen oder selbst in den Prozess eingreifen. Um diesen Status zu erreichen, muss allerdings ein initialer Aufwand betrieben werden: Es müssen genügend Messwerte ausreichender Qualität für die Modellbildung vorhanden sein, die Modellierung erfordert Know-how im Bereich der Data Science und das Prozessleitsystem muss über passende Schnittstellen für den Datenaustausch verfügen. In diesem Artikel wurden aktuelle Ansätze gezeigt, die eine Lösung dieser Herausforderungen mit wenig Aufwand ermöglichen und auf diese Weise den Einsatz digitaler Systeme auch in der eher konservativ geprägten Industrie vorantreiben.
Autor: M. Sc. Jonathan Sturm, Westfälische Hochschule, Recklinghausen
____________________________
Literatur
[1] Steck, H. et al.: “Deep Learning for Recommender Systems: A Netflix Case Study,” AI Mag., vol. 42, no. 3, pp. 7–18, Nov. (2021)
[2] Fisher, O. J. et al.: “Considerations, challenges and opportunities when developing data-driven models for process manufacturing systems,” Comput. Chem. Eng., vol. 140, p. 106881, Sep. (2020)
[3] Rodrigues, F. et al.: “Sugar Metabolism in Yeasts: an Overview of Aerobic and Anaerobic Glucose Catabolism,” in Biodiversity and Ecophysiology of Yeasts, Berlin/Heidelberg: Springer-Verlag, pp. 101–121. (2006)
[4] Sturm, J. and Eiden, F.: “Prozessentwicklung in der KI-Cloud,” GIT Labor-Fachzeitschrift (Wiley), (2020)
[5] Mahnke W. et al.: OPC Unified Architecture. Berlin, Heidelberg: Springer Berlin Heidelberg, (2009)










